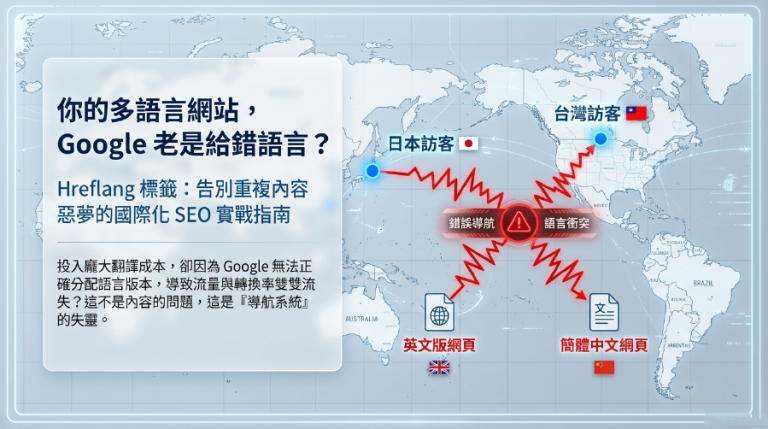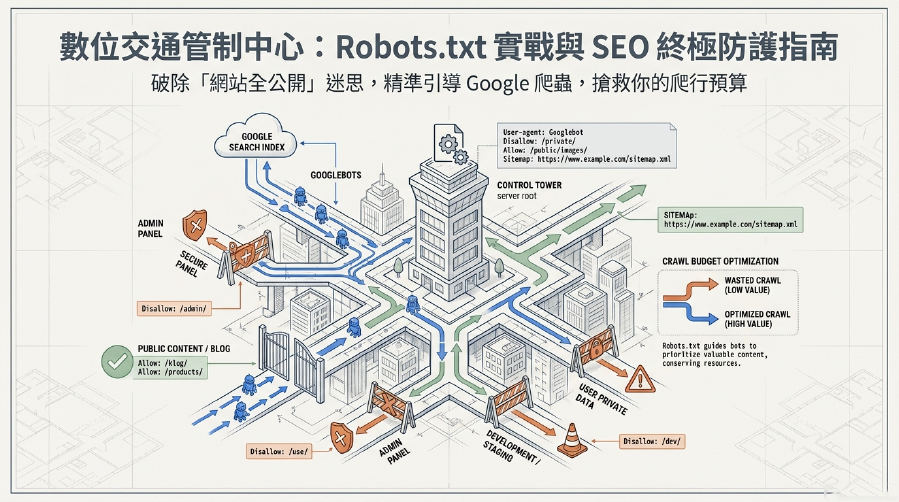
Robots.txt教學:你的網站,是讓Google「亂竄」還是「乖乖聽話」?這樣設定,讓SEO更給力!
你的網站是不是也像個沒有紅綠燈的城市,讓Google的「小汽車」(也就是Google 爬蟲)在裡面亂竄,把一些根本不想給人看、沒意義的頁面也收錄進去了?更糟的是,你可能還沒意識到,這些多餘的爬取不僅浪費了Google的資源,也消耗了你網站寶貴的爬行預算 (Crawl Budget),甚至還可能導致重複內容問題,讓你的SEO 優化效果大打折扣,最終影響你的網站索引表現,讓你的好內容被「埋沒」?
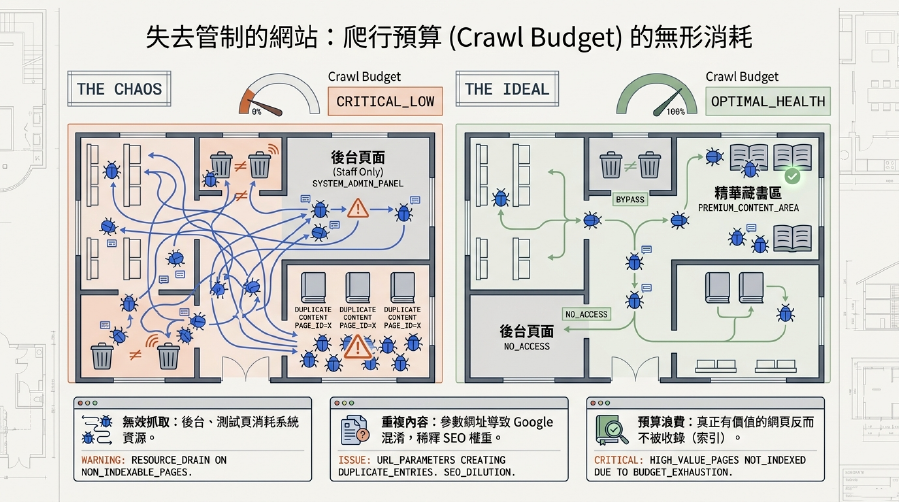
想像一下,你家有個超級大的圖書館(你的網站),裡面有好多重要的書(對SEO有益的內容),但也堆放了一些正在整理、不適合公開的雜物或私人信件(後台頁面、測試頁、重複內容)。如果沒有一個圖書館管理員(Robots.txt),所有訪客(Google 爬蟲)都可以隨意進出、翻閱,把你的雜物也拍下來公開,是不是很令人頭大?
別擔心!今天我們就是要來當你的網站「交通指揮官」!這篇文章將帶你輕鬆搞懂Robots.txt這個檔案到底是什麼,以及如何利用它來精準地引導Google 爬蟲,讓它只爬取對你的SEO 優化有幫助的頁面,同時有效避免重複內容問題,將無用的頁面進行禁止抓取。我們還會手把手教你如何將它與Sitemap (網站地圖) 和Google Search Console完美結合,制定一套無懈可擊的SEO 策略,最終大幅提升你的網站索引效率,讓你的網站SEO表現更上一層樓!準備好了嗎?讓我們一起來學習如何讓Google「乖乖聽話」吧!
你的網站,是「開放式」還是「管制區」?Robots.txt的重要性!
你可能會想,我網站反正都是公開的,為什麼還要特別設定什麼Robots.txt?這就大錯特錯了!Robots.txt就像是你網站的「守門人」兼「交通規則」,它的存在有著你意想不到的重要性。
1. 指揮Google爬蟲:哪裡該去,哪裡不該去!
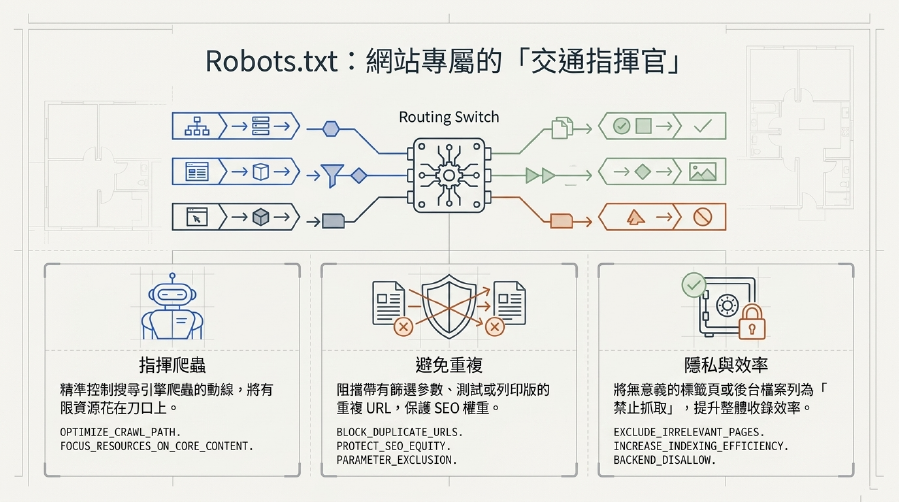
Robots.txt是一個純文字檔案,它的主要任務就是告訴Google 爬蟲(以及其他搜尋引擎爬蟲)在你的網站上哪些區域可以訪問,哪些區域應該禁止抓取。這就像你對圖書館管理員說:「這些書架上的書都可以給人看,但那個寫著『員工專用』的房間,請不要讓外人進去!」
透過這個檔案,你可以精準地控制爬蟲的行為,確保它將有限的資源(爬行預算 (Crawl Budget))花費在對你最重要的頁面上,而不是在一些不相關、甚至有害的頁面上徘徊。
2. 避免重複內容問題:保護你的SEO權重!
重複內容問題是SEO的一大殺手!很多時候,你的網站可能會因為技術原因(例如帶有篩選參數的頁面、測試頁、列印版頁面)產生內容重複的URL。如果這些重複的頁面都被Google 爬蟲抓取並網站索引,Google就會感到困惑,不知道哪個才是「原版」,可能會稀釋你的SEO權重,甚至影響你的排名。
而Robots.txt就能派上用場了!你可以透過它來禁止抓取這些重複內容頁面,告訴Google:「這些頁面是複製的,不用費心去抓取和索引了。」這樣就能有效避免重複內容問題,集中你的SEO權重,提升SEO 優化效率。
3. 保護隱私與效率:不想給人看的,就別讓Google來!
你的網站後台、開發中的測試頁面、或一些用戶私密資料頁面,這些都是不希望被Google 爬蟲抓取,更不希望被網站索引到搜尋結果中的。Robots.txt提供了一個簡單有效的方法來實現這一點。
同時,對於一些有大量無用或低質量頁面(例如無意義的標籤頁、搜尋結果頁面)的網站,透過Robots.txt禁止抓取它們,也能節省爬行預算,讓Google 爬蟲更高效地找到你真正重要的內容。這是每個網站都應具備的基本SEO 策略。
Robots.txt的「交通規則」:基本語法大解密!
Robots.txt檔案的語法非常簡單,主要由幾個關鍵指令組成。你只需要理解這些指令,就能輕鬆設定你的網站「交通規則」!
它通常會放在網站的根目錄下,例如 你的網站.com/robots.txt。
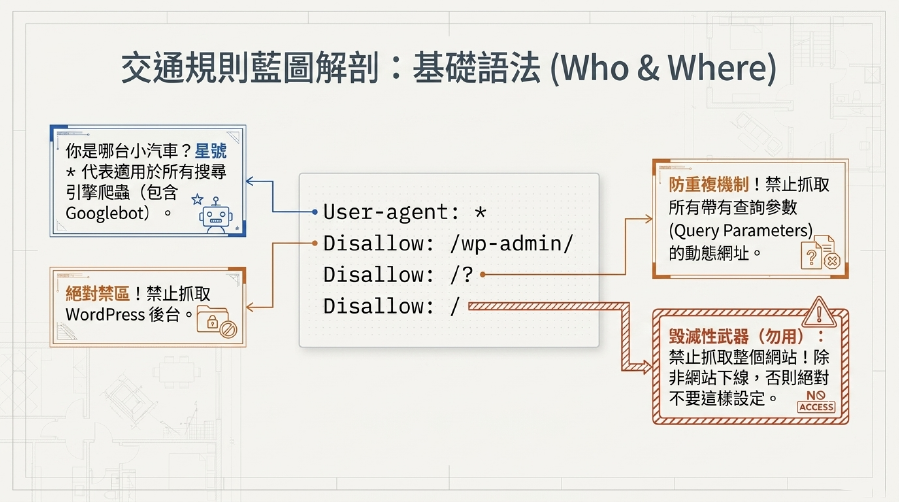
1. User-agent:你是哪台「小汽車」?
這個指令用來指定你希望對哪種Google 爬蟲(或其他搜尋引擎爬蟲)生效。
-
-
User-agent: *:這個星號*代表「所有搜尋引擎爬蟲」。這是最常見的設定,表示你下面的規則適用於所有爬蟲。User-agent: Googlebot:只針對Google的通用爬蟲。User-agent: Googlebot-Image:只針對Google的圖片爬蟲。User-agent: AdsBot-Google:只針對Google廣告爬蟲。- 技巧: 如果你沒有特別需求,
User-agent: *就可以了。
-
2. Disallow:這個地方「禁止進入」!
這是Robots.txt最核心的指令,用來告訴Google 爬蟲哪些路徑或檔案是禁止抓取的。
-
-
Disallow: /:這是個「大殺器」,表示禁止抓取整個網站!除非你網站還在建設中或需要暫時下線,否則千萬不要這樣設定!這會導致你的網站無法被網站索引。Disallow: /wp-admin/:禁止抓取WordPress後台管理頁面。這是常見且推薦的設定,因為這些頁面不應該出現在搜尋結果中。Disallow: /private-folder/:禁止抓取網站根目錄下名為private-folder的資料夾及其所有內容。Disallow: /file.pdf:禁止抓取名為file.pdf的檔案。Disallow: /?:禁止抓取所有帶有查詢參數的URL,這對於避免重複內容問題非常有用,例如你的網站.com/?p=123。
-
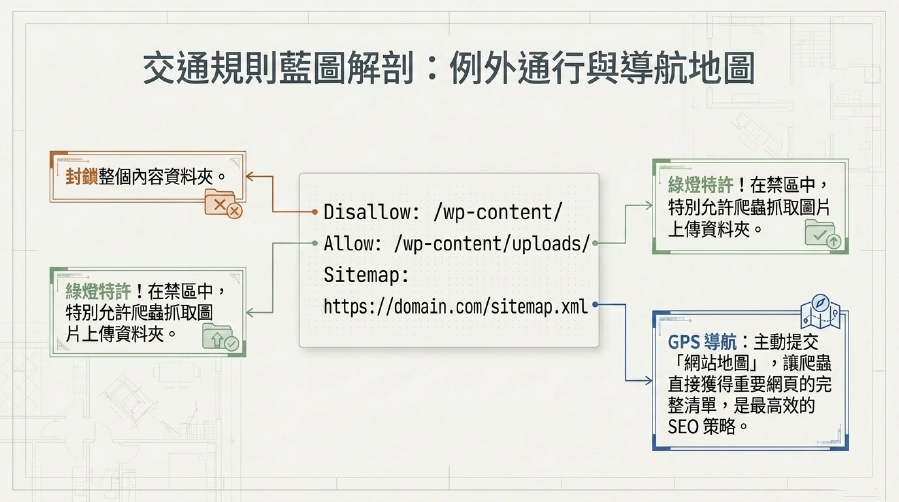
3. Allow:這個地方「可以進入」!
Allow 指令相對少見,它用於在一個已被 Disallow 的目錄中,特別允許抓取某些子目錄或檔案。
-
-
- 情境: 如果你禁止抓取了整個
/wp-content/資料夾,但又希望爬蟲能抓取/wp-content/uploads/裡的圖片,就可以這樣寫:
User-agent: *
Disallow: /wp-content/
Allow: /wp-content/uploads/
這樣,爬蟲就知道
/wp-content/的大部分內容不能碰,但/wp-content/uploads/是OK的。
- 情境: 如果你禁止抓取了整個
-
4. Sitemap:你的「網站地圖」在哪?
這個指令是告訴Google 爬蟲你的Sitemap (網站地圖) 檔案在哪裡。Sitemap是另一個非常重要的SEO檔案,它會列出你網站所有希望被網站索引的頁面。
-
-
Sitemap: https://你的網站.com/sitemap_index.xml:這是將Robots.txt與Sitemap (網站地圖) 結合的標準做法。透過這個指令,Google 爬蟲可以快速找到你的Sitemap (網站地圖),從而更高效地抓取和索引你的重要頁面,這對你的SEO 策略至關重要。
-
最常見的「禁止抓取」情境:哪些頁面不給Google看?
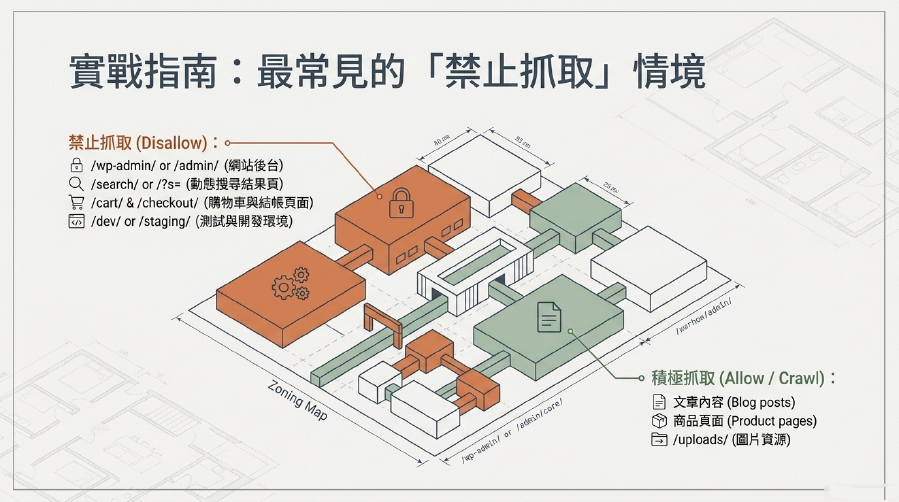
為了更好的SEO 優化,以下是一些你通常會考慮在Robots.txt中禁止抓取的頁面或目錄:
-
- 網站後台:
/wp-admin/(WordPress)、/admin/(通用) - 主題/外掛資料夾:
/wp-content/plugins/、/wp-content/themes/(但通常會允許/uploads/資料夾) - 測試或開發環境:
/dev/、/staging/ - 搜尋結果頁面:
/search/、/?s=(因為這些頁面通常是動態生成且內容重複性高) - 購物車/結帳頁面:
/cart/、/checkout/(這些頁面不應該被索引) - 用戶個人資料頁面:
/my-account/、/profile/ - 帶有Session ID或過濾參數的URL: 這些是常見的重複內容問題來源,例如
/?filter=price&color=red。
- 網站後台:
讓Google Search Console成為你的「監工」:檢查Robots.txt是否生效!
設定好Robots.txt檔案後,千萬別忘了驗證它是否正確運作!這時候,Google Search Console就是你最好的朋友了。
1. Robots.txt測試工具 (Robots.txt Tester)
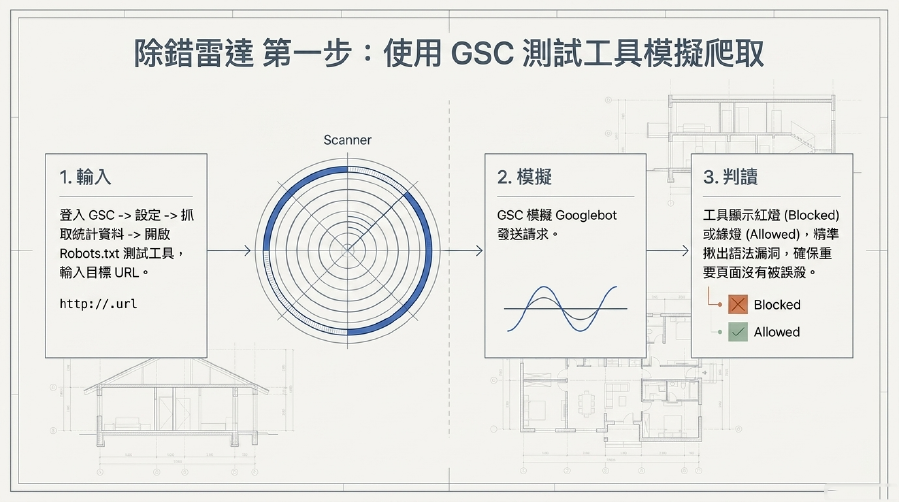
Google Search Console內建了一個「Robots.txt測試工具」。
-
-
- 怎麼用? 登入你的Google Search Console帳戶,在左側導航欄找到「設定」->「抓取統計資料」-> 點擊「開啟報告」後,通常會看到相關的連結或工具入口。輸入你想要測試的URL,它會模擬Google 爬蟲,告訴你這個URL是否被Robots.txt所禁止抓取。
- 目的: 這個工具可以幫助你快速檢查你的Robots.txt語法是否有錯誤,以及你的
Disallow規則是否按預期生效,確保你的SEO 策略沒有「漏洞」。
-
2. 索引涵蓋範圍報告

在GSC的「索引 > 網頁」報告中,你會看到Google 爬蟲對你網站的網站索引情況。
-
-
- 看什麼? 如果你的Robots.txt設定正確,那些被你禁止抓取的頁面應該會顯示為「已排除:經由 robots.txt 封鎖」。這表示Robots.txt已經成功地阻止了Google 爬蟲。
- 小提醒: 如果你發現某些重要頁面被Robots.txt錯誤地禁止抓取,GSC也會在這裡發出警告,讓你及時修復。
-
Robots.txt的「雙面刃」:常見錯誤與SEO策略!
Robots.txt很強大,但用錯了也會變成「雙面刃」,反而傷害你的SEO 優化。
1. 錯誤地禁止抓取重要頁面:自廢武功!
這是最常見、也最致命的錯誤!如果你不小心在Robots.txt中禁止抓取了重要的內容頁面、分類頁面或商品頁面,那麼Google 爬蟲就無法抓取這些頁面,它們也就不會出現在網站索引中,你的網站流量和排名自然就會受影響。
-
-
- 建議: 永遠要仔細檢查你的Robots.txt檔案,並使用GSC的測試工具確認沒有誤傷重要頁面。
-
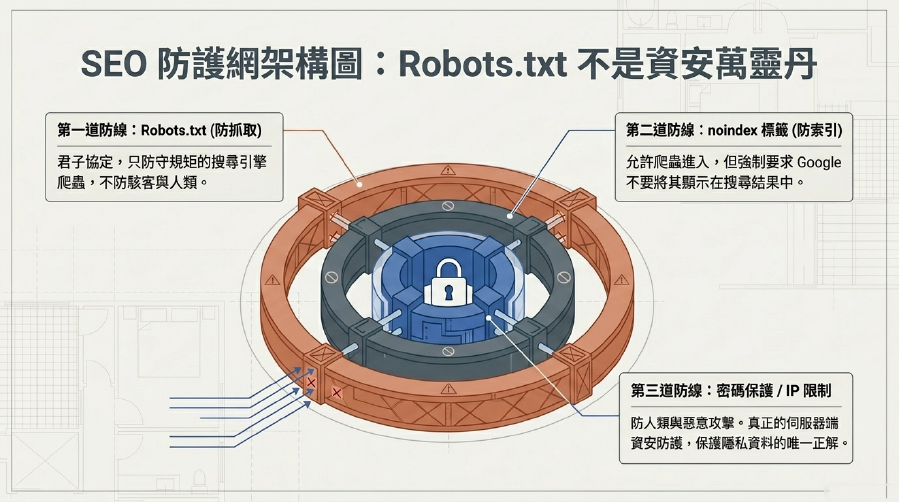
2. 認為Robots.txt能「隱藏」私密資料:大錯特錯!
Robots.txt只能指示Google 爬蟲不要抓取,但它不能阻止其他網站連結到你的頁面,也不能阻止用戶直接訪問這些頁面(如果他們知道URL)。Robots.txt並不是一個安全機制!
-
-
- 建議: 如果你的內容是敏感或私密的,應該使用密碼保護、IP限制或其他更強的安全性措施,而不是單純依賴Robots.txt。
-
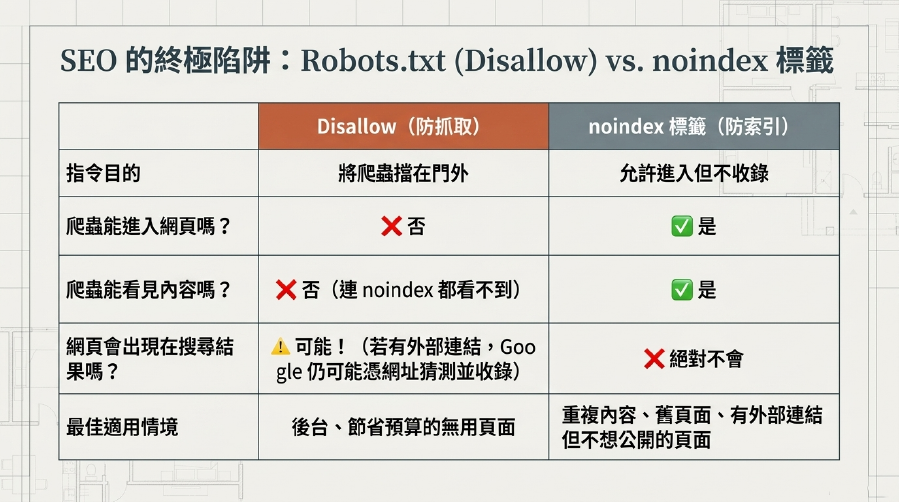
3. 與noindex標籤混淆:爬取與索引的區別!
這是SEO 優化中一個常見的誤解。
-
-
- Robots.txt的
Disallow:告訴Google 爬蟲「不要來抓取這個頁面」。如果頁面沒有被抓取,它自然也就不會被網站索引。 noindex標籤:告訴Google 爬蟲「你可以來抓取這個頁面,但請不要將它收錄到索引中」。noindex通常放在頁面的<head>區塊。- 什麼時候用哪個?
- 如果你確定一個頁面完全不希望被Google訪問和索引,就用Robots.txt的
Disallow。例如後台頁面。 - 如果你希望Google 爬蟲能訪問頁面,但不要顯示在搜尋結果中(例如重複內容頁面,或者想讓權重流失掉的舊頁面),那麼
noindex標籤是更好的選擇。因為如果你的Disallow阻止了爬蟲,爬蟲就看不到noindex標籤,反而可能導致Google根據外部連結的錨文本來「猜測」並索引你的頁面,造成意外的網站索引問題。 - SEO 策略建議:對於要禁止抓取的頁面,如果沒有其他網站會連結到它,
Disallow是個好選擇。如果有外部連結或內部連結指向它,但你不想它被索引,使用noindex標籤會更精準。
- 如果你確定一個頁面完全不希望被Google訪問和索引,就用Robots.txt的
- Robots.txt的
-
掌握Robots.txt,讓你的網站SEO衝刺起飛!
恭喜你!讀到這裡,你已經不再是對Robots.txt一知半解的小白了!我們一起深入探討了Robots.txt的重要性,它如何像網站的「交通指揮官」,引導Google 爬蟲,節省寶貴的爬行預算 (Crawl Budget),有效避免重複內容問題,並透過禁止抓取來保護你的隱私與效率。
我們也學習了Robots.txt的基本語法,包括User-agent、Disallow、Allow以及如何結合Sitemap (網站地圖),制定出高效的SEO 策略。更重要的是,你現在知道如何利用Google Search Console的測試工具來驗證你的設定,確保你的SEO 優化工作萬無一失,讓你的網站索引效率達到最高。
記住,Robots.txt雖然只是一個小小的文字檔案,但它卻是管理Google 爬蟲行為、提升網站SEO效能的關鍵工具。現在就去檢查你的Robots.txt檔案吧!確保它能正確地引導Google 爬蟲,讓你的網站內容在搜尋引擎中發光發熱,衝刺更高的排名和更多的流量!

常見問題 (FAQ)
1. Q: Robots.txt可以禁止Google索引我的網頁嗎?
A: Robots.txt本身的主要功能是禁止抓取(Disallow),它告訴Google 爬蟲「不要訪問這個頁面」。如果一個頁面沒有被抓取,那麼它通常也就不會被網站索引。然而,這並非100%保證。如果其他網站有連結到你的被Disallow的頁面,Google仍可能會在搜尋結果中顯示該頁面的URL,只是沒有頁面內容的摘要。要明確禁止網站索引,更可靠的方法是在頁面HTML的<head>區塊中加入meta name="robots" content="noindex"標籤。
2. Q: 如果我的網站沒有Robots.txt檔案會怎樣?
A: 如果你的網站沒有Robots.txt檔案,這表示你沒有對Google 爬蟲設置任何禁止抓取的規則。在這種情況下,Google 爬蟲將會嘗試抓取你的網站所有可訪問的頁面,這包括你的後台、測試頁面、或可能產生重複內容問題的頁面。這可能會浪費你的爬行預算 (Crawl Budget),並導致一些不必要的頁面被網站索引。為了有效的SEO 優化和SEO 策略,建議還是建立一個合適的Robots.txt檔案。
3. Q: Robots.txt和noindex標籤有什麼根本區別?
A: 兩者都是控制Google 爬蟲行為的工具,但作用點不同: * Robots.txt (Disallow): 阻止Google 爬蟲訪問和抓取你的頁面。如果爬蟲無法訪問頁面,它也看不到頁面上的內容(包括noindex標籤)。 * noindex標籤 (<meta name="robots" content="noindex">): 允許Google 爬蟲訪問和抓取你的頁面,但指示它不要將該頁面收錄到網站索引中。 所以,如果一個頁面包含noindex標籤,但又被Robots.txt的Disallow指令禁止抓取,那麼Google 爬蟲就看不到noindex標籤,反而可能造成頁面被索引的意外情況。通常對於需要被抓取但不想被索引的頁面,noindex標籤是更精準的SEO 策略。
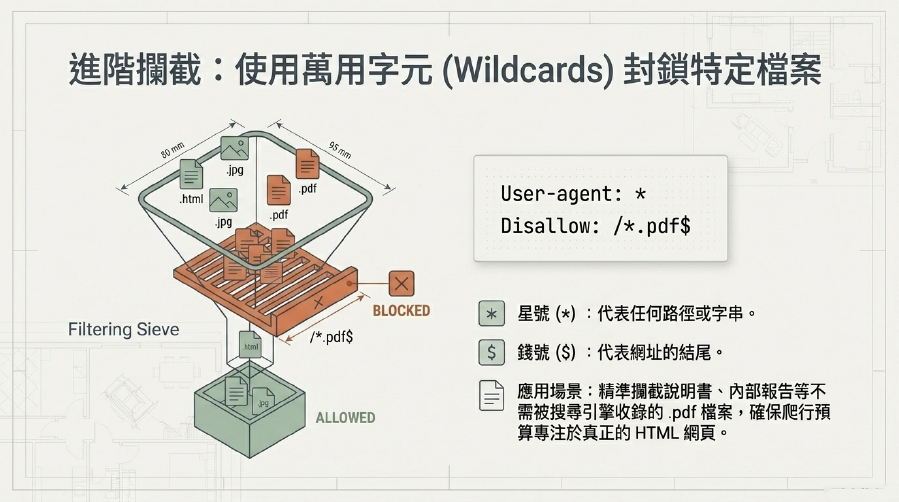
4. Q: 我可以使用Robots.txt禁止抓取特定檔案類型嗎?例如只禁止PDF檔案?
A: 可以的。你可以在Robots.txt檔案中使用通配符 * 來匹配特定的檔案類型。例如,如果你想禁止抓取網站上的所有PDF檔案,可以這樣寫:
User-agent: *
Disallow: /*.pdf$
這個規則表示,對所有Google 爬蟲,禁止抓取任何以.pdf結尾的URL。這對於管理某些不需要被網站索引的資源檔案(如說明書、內部報告)非常有用,有助於SEO 優化。
5. Q: Robots.txt會影響網站安全嗎?
A: Robots.txt與網站安全無關。它只是一個「公開的君子協定」,用來引導Google 爬蟲等合法爬蟲的行為,告訴它們哪些區域不應該被抓取。它不能阻止惡意爬蟲或直接的駭客攻擊。任何用戶或工具只要知道你的URL,仍然可以直接訪問那些被Robots.txtDisallow的頁面。因此,對於需要保護的敏感內容,你必須依賴更強大的安全措施,如伺服器端認證、防火牆、或檔案權限設置,而不是僅僅依靠Robots.txt。