你的網站Google爬蟲老是「迷路」?爬行預算優化,讓Google高效爬取,網站索引飆升!
你的網站是不是明明內容很豐富,頁面也很多,但Google搜尋結果的網站索引優化卻遲遲無法突破?或者,你總覺得Google爬蟲好像只爬取了你網站的一部分內容,很多重要頁面遲遲不見動靜?你可能還不曉得,問題很可能就出在一個看似不起眼,卻對網站SEO至關重要的概念上—「Crawl Budget (爬行預算)」!

想像一下,Google的Google 爬蟲效率就像一個快遞小哥,每天要派送大量的包裹(抓取你的網站內容)。但這個小哥的時間和精力(Crawl Budget (爬行預算))是有限的!如果你家的包裹雜亂無章、有些是垃圾、有些地址還寫錯了,那小哥是不是就會把有限的時間浪費在這些無用或錯誤的包裹上,而延誤了那些真正重要、需要派送的包裹?你的網站也是一樣的道理!如果沒有做好爬行預算優化,Google爬蟲就會把寶貴的資源浪費在低質量、重複內容或已經失效的頁面上,導致真正重要的內容無法被及時網站索引優化,嚴重影響你的SEO 網站排名!
別擔心!今天我們就是要來當你的「爬行預算管理大師」!這篇文章將帶你深度解析什麼是Crawl Budget (爬行預算),為什麼它對你的Google 爬蟲效率和網站索引優化如此重要。我們將手把手教你如何透過Robots.txt、Sitemap (網站地圖)、重複內容管理和內部連結優化等策略,精準引導Google爬蟲,讓它更高效地爬取你的網站。我們還會分享如何利用Google Search Console 爬取功能來監控與排查問題。只要掌握這些關鍵技巧,你就能讓你的網站內容被Google爬蟲徹底「看懂」,確保所有寶藏都被發現並收錄,最終讓你的網站流量像火箭一樣飆升!準備好了嗎?讓我們一起開始這場「爬行預算優化大作戰」吧!
Crawl Budget (爬行預算):Google爬蟲的「時間與精力」!為何它決定你的網站索引?
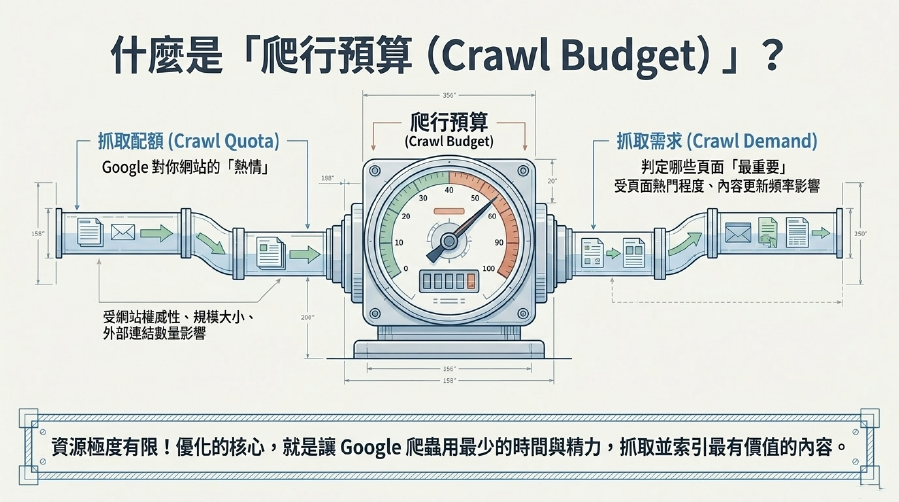
你可能會覺得,Google這麼強大,應該能抓取我網站上所有頁面吧?是的,但它有「效率問題」!Crawl Budget (爬行預算) 是Google爬蟲在一定時間內,在你的網站上願意花費的資源(包括時間和抓取請求數量)。理解它,是進行網站索引優化和提升Google 爬蟲效率的關鍵。
1. 抓取配額 (Crawl Quota):Google對你網站的「熱情」!
Google會根據你網站的權威性、更新頻率、規模大小、外部連結數量等因素,分配一個「抓取配額」。這個配額決定了Google爬蟲在特定時間內,在你的網站上能花多少時間和發送多少次請求。
-
-
- 影響: 如果你的網站內容更新頻繁、頁面眾多,但Google分配的抓取配額有限,那麼許多新內容可能無法及時被發現和網站索引優化。
- 優化目標: 透過爬行預算優化,提升Google對你網站的「熱情」,爭取更多的抓取配額。
-
2. 抓取需求 (Crawl Demand):哪些頁面最重要?
Google也會根據你網站頁面的熱門程度、內容更新頻率、外部連結數量等因素,判斷哪些頁面應該優先被抓取。
-
-
- 影響: 如果你網站上充斥著大量低質量、重複內容或已經失效的頁面,Google爬蟲可能會浪費資源在這些無用的頁面上,而忽略你真正重要、有價值的內容。
- 優化目標: 透過爬行預算優化,引導Google爬蟲優先抓取你最重要的頁面,提升Google 爬蟲效率。
-
所以,Crawl Budget (爬行預算) 的優化,核心就是:讓Google爬蟲用最少的時間和精力,抓取到你網站上最有價值的內容,並確保這些內容被高效地網站索引優化!
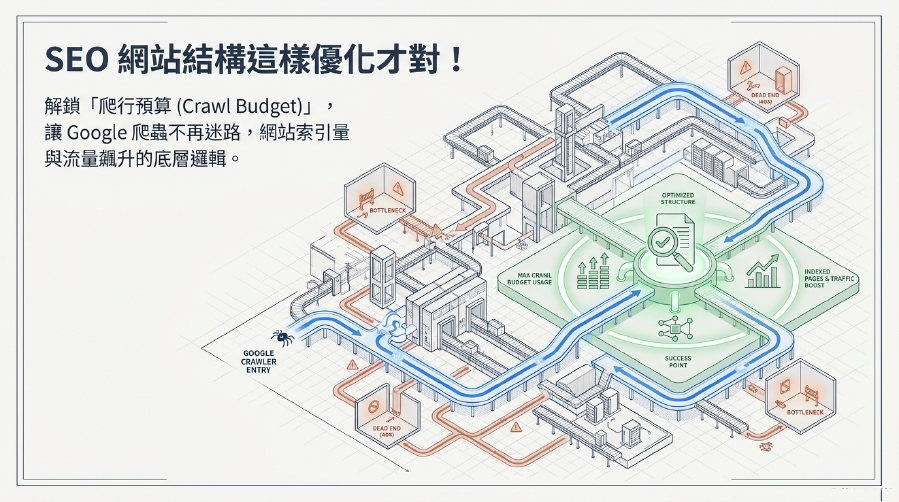
爬行預算優化:讓Google爬蟲「精打細算」,專注抓取有價內容!

要讓Google爬蟲高效工作,你需要清除路障、提供地圖、並明確指示重點!
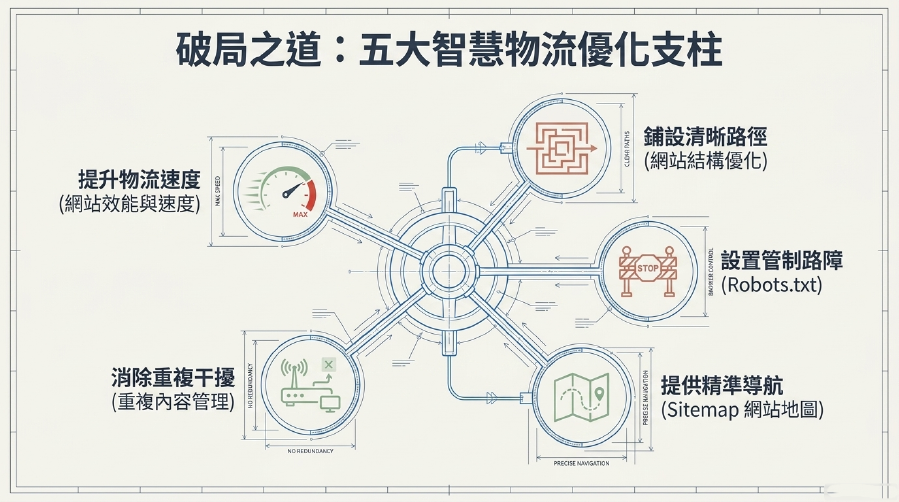
1. 網站結構優化 (SEO Website Structure):清晰的路徑,不讓Google迷路!
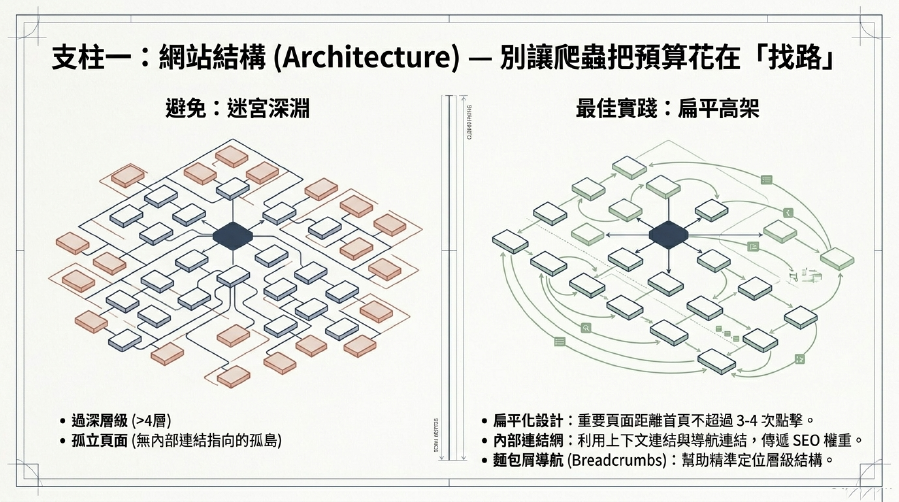
一個扁平、邏輯清晰的SEO 網站結構,能讓Google爬蟲更容易理解網站的層次和內容關聯性,有效提升Google 爬蟲效率。
-
-
- 減少深度: 確保重要頁面距離首頁的點擊次數越少越好(通常不超過3-4層)。
- 內部連結優化: 建立強大且相關的內部連結系統。
- 上下文連結: 在文章內容中連結到其他相關頁面。
- 導航連結: 確保網站主要導航包含所有重要分類和頁面。
- 減少孤立頁面: 避免有任何頁面沒有內部連結指向它。
- 麵包屑導航 (Breadcrumbs): 幫助用戶和爬蟲理解頁面在網站結構中的位置。
- 好處: 爬蟲能更快找到所有頁面,將Crawl Budget (爬行預算) 用在抓取內容而不是「尋路」上。
-
2. Robots.txt管理:告訴Google爬蟲「哪裡不該去」!
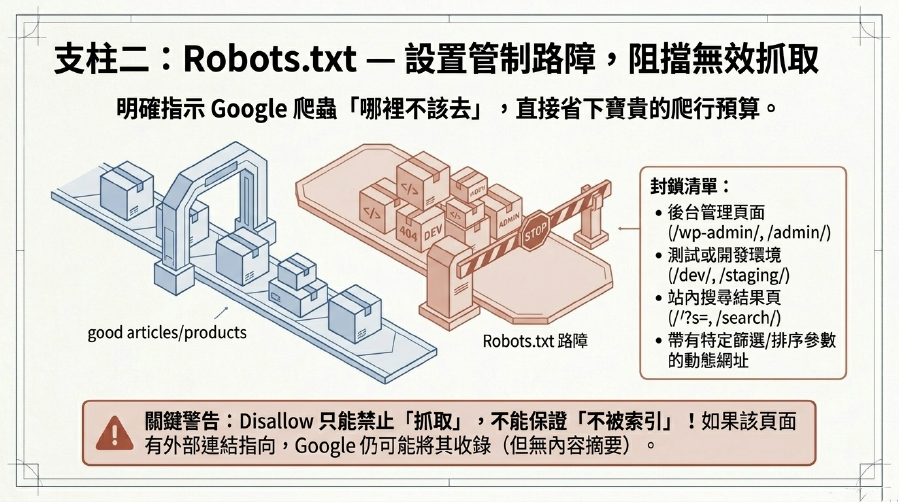
Robots.txt檔案是用來告知Google爬蟲哪些頁面或目錄是禁止抓取的。這是最直接的爬行預算優化工具。
-
-
- 禁止抓取無用頁面:
- 後台管理頁面(
/wp-admin/、/admin/) - 測試或開發環境(
/dev/、/staging/) - 搜尋結果頁面(
/?s=、/search/) - 帶有特定參數的頁面(例如篩選、排序參數)
- 重複內容、低質量內容、或敏感資訊頁面
- 後台管理頁面(
- 小提醒:
Disallow只能禁止抓取,不能禁止索引!如果頁面有外部連結指向,Google仍可能索引,只是沒有內容摘要。要徹底不索引,需要配合noindex標籤。 - 好處: 將Google爬蟲的資源集中在對你最重要的頁面上,避免Crawl Budget (爬行預算) 浪費在無關緊要的頁面。
- 禁止抓取無用頁面:
-
3. Sitemap (網站地圖) 優化:給Google一份「精準地圖」!
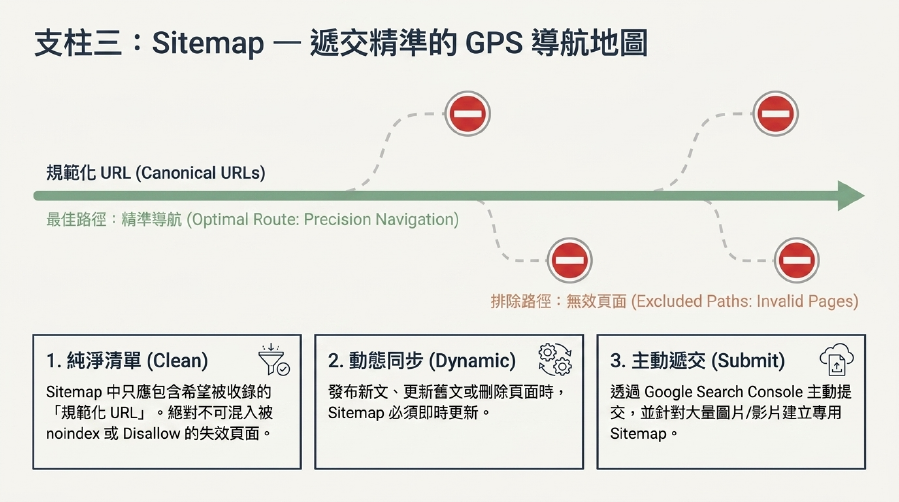
Sitemap (網站地圖) 是一個列出你網站所有重要URL的XML檔案。它是引導Google爬蟲的「地圖」,對於網站索引優化至關重要。
-
-
- 包含規範URL: 你的Sitemap中應該只包含你希望Google爬取和索引的「規範URL」。不要包含被
noindex或Disallow的頁面。 - 定期更新: 當你發布新內容、更新舊內容或刪除頁面時,務必更新你的Sitemap。
- 提交給Google Search Console 爬取: 在GSC中提交你的Sitemap,確保Google能快速發現所有重要頁面。
- 影片Sitemap/圖片Sitemap: 如果你有大量影片或圖片內容,可以創建專用的Sitemap。
- 好處: 確保Google爬蟲能快速發現所有重要頁面,提升Google 爬蟲效率和網站索引優化。
- 包含規範URL: 你的Sitemap中應該只包含你希望Google爬取和索引的「規範URL」。不要包含被
-
4. 重複內容管理:消除Google爬蟲的「選擇困難」!
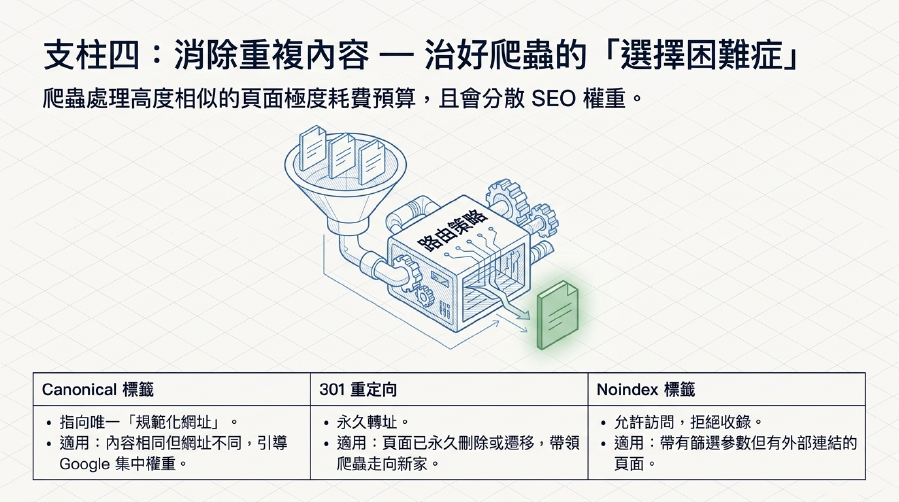
重複內容管理是爬行預算優化的關鍵一環。Google爬蟲花費大量資源去抓取和分析重複內容,會大大降低效率。
-
-
- Canonical 標籤: 對於內容相同或高度相似的頁面,使用Canonical 標籤明確指出哪個是「規範化網址」,引導Google將SEO 權重集中。
- 301重定向: 對於已永久刪除或遷移的頁面,使用301 重新導向到新的相關頁面。
noindex標籤: 對於不想被索引的低質量或重複內容頁面,但又不想禁止抓取(例如帶有篩選參數的頁面),使用noindex標籤。- 好處: 減少Google爬蟲處理重複內容的時間,將Crawl Budget (爬行預算) 集中在有價值的內容上。
-
5. 網站速度優化:更快載入,更快抓取!
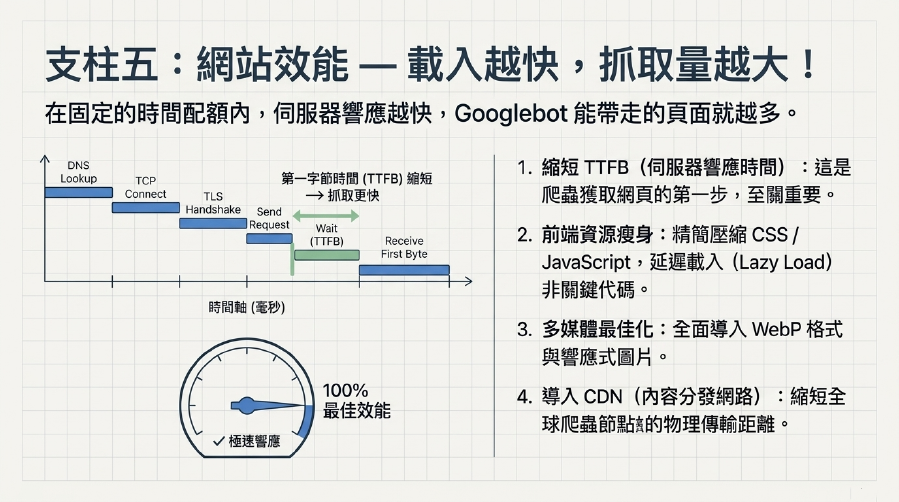
Google 爬蟲效率和你的網站速度息息相關。Google爬蟲也喜歡訪問載入速度快的網站!
-
-
- 提升伺服器響應時間 (TTFB): 這是 Google 爬蟲獲取頁面內容的第一步。快速的伺服器響應能讓爬蟲在同樣時間內抓取更多頁面。
- 優化圖片: 壓縮、WebP格式、Lazy Load、響應式圖片,減少圖片載入時間。
- 精簡CSS和JavaScript: 壓縮、最小化、延遲載入非關鍵JS/CSS。
- 使用CDN: 內容分發網路,縮短內容傳輸距離。
- 好處: 更快的網站速度意味著Google爬蟲可以在同樣的Crawl Budget (爬行預算) 內,抓取更多的頁面,進一步提升網站索引優化。
-
Google Search Console 爬取功能:監控你的「爬行預算」!

Google Search Console (GSC) 是你監控Crawl Budget (爬行預算) 和Google 爬蟲效率的最佳工具。
1. 爬取統計資料報告 (Crawl Stats Report):掌握爬蟲的「活動量」!
在GSC的「設定」->「抓取統計資料」報告中,你可以看到Google爬蟲在你的網站上的活動情況:
-
-
- 總爬取請求數: Google每天爬取你的頁面數量。
- 總下載大小: 每次爬取下載的數據總量。
- 平均回應時間: 伺服器對Google爬蟲請求的平均回應速度。
- 按狀態碼分類的請求: 顯示200 (OK)、301 (重定向)、404 (未找到) 等不同HTTP 狀態碼的請求數量。
- 按檔案類型分類的請求: 顯示HTML、圖片、JS、CSS等不同檔案類型的爬取情況。
- 按Googlebot類型分類的請求: 顯示是通用爬蟲、圖片爬蟲還是其他類型爬蟲。
- 用途: 這些數據能幫助你判斷Google 爬蟲效率是否正常,是否有大量的404或5xx錯誤,以及爬蟲資源是否被浪費在不必要的檔案上。
-
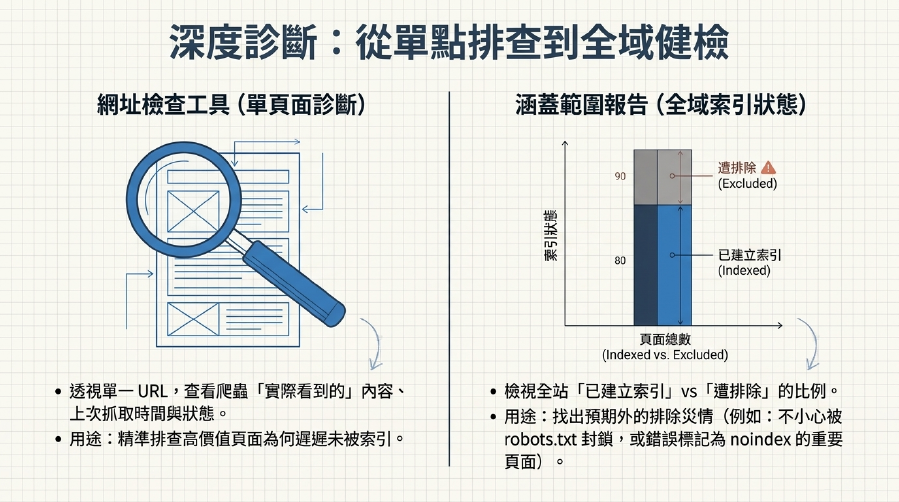
2. 網址檢查工具 (URL Inspection Tool):單頁面的「爬取診斷」!
輸入任何一個你網站的URL,GSC會顯示Google爬蟲「看到的」你的頁面內容,以及上次爬取時間、爬取狀態等。
-
-
- 用途: 檢查特定頁面是否被爬取、索引,以及是否存在抓取問題,這對排查網站索引問題非常有效。
-
3. 索引涵蓋範圍報告 (Index Coverage Report):你的「索引狀態」總覽!
查看GSC的「索引」->「網頁」報告,你會看到哪些頁面已被索引、哪些被排除,以及排除的原因(例如「經由robots.txt封鎖」、「已提交的網址標記為noindex」等)。
-
-
- 用途: 判斷你的爬行預算優化策略是否有效,重要頁面是否被成功索引,以及是否存在未預期的網站索引問題。
-
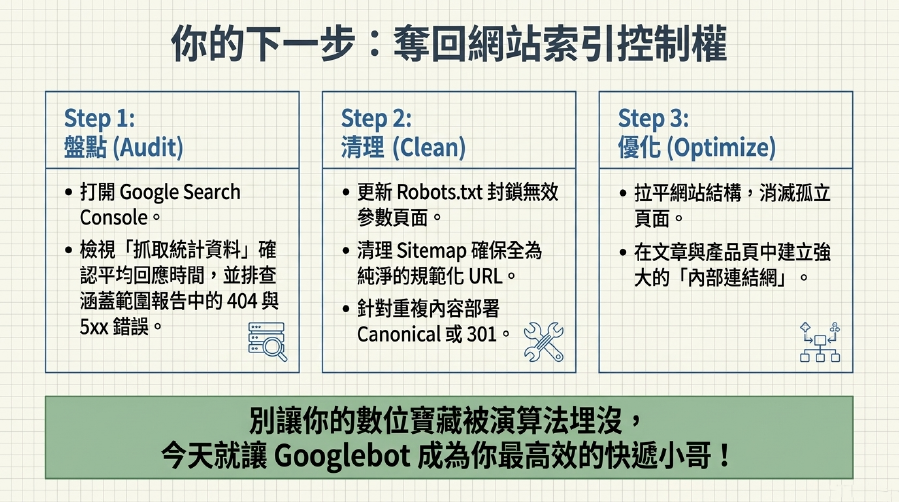
Crawl Budget優化,讓Google爬蟲成為你網站的「最佳夥伴」!
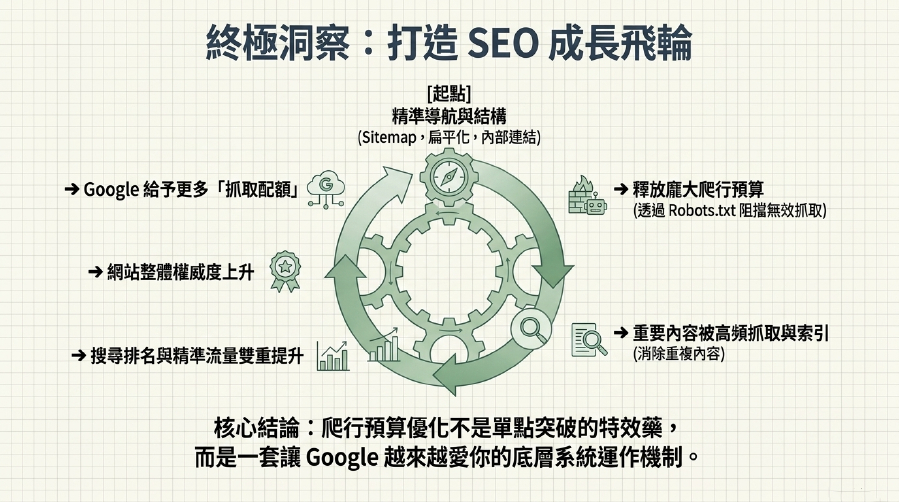
恭喜你!讀到這裡,你已經成功解鎖了Crawl Budget (爬行預算) 優化這個對Google 爬蟲效率和網站索引優化至關重要的「秘密武器」!我們一起深入了解了爬行預算如何影響Google對你網站的「熱情」和抓取需求,以及它對你SEO 網站排名的深遠影響。
我們也掌握了如何透過SEO 網站結構優化、Robots.txt管理、Sitemap (網站地圖) 優化、重複內容管理和網站速度優化等策略,精準引導Google爬蟲。最重要的是,你現在知道了如何利用Google Search Console 爬取功能,像「偵探」一樣監控Google 爬蟲行為,發現並解決網站索引問題。
請記住,Crawl Budget (爬行預算) 優化不是一個可有可無的選項,而是你網站生存發展的「必修課」,特別是對於大型網站。現在就行動起來,讓你的網站內容被Google爬蟲徹底「看懂」,確保所有寶藏都被發現並收錄,最終讓你的網站流量像火箭一樣飆升,業務蒸蒸日上!
常見問題 (FAQ)
1. Q: 我的網站頁面不多,還需要做Crawl Budget (爬行預算) 優化嗎?
A: 是的,即使你的網站頁面不多,優化Crawl Budget (爬行預算)仍然很重要! 對於小型網站,Google爬蟲訪問頻率通常較高。但如果你網站有很多低質量、重複或不重要的頁面,Google爬蟲可能會浪費資源在這些頁面上,而忽略你真正重要的內容。透過爬行預算優化,你可以確保Google爬蟲將其有限的資源集中在對你最重要的頁面上,提升Google 爬蟲效率,確保所有重要頁面都被及時網站索引優化。這也是良好的SEO 網站結構維護習慣。
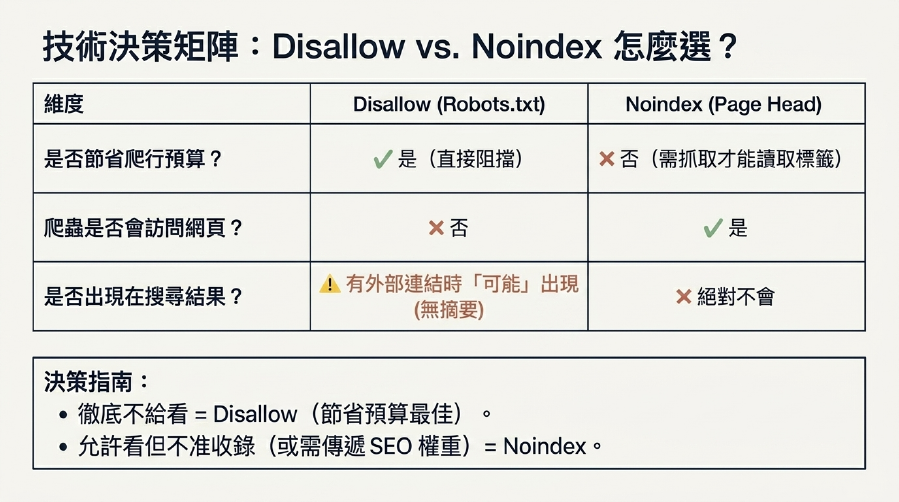
2. Q: Robots.txt中的Disallow和noindex標籤有什麼區別?哪個對Crawl Budget (爬行預算)優化更有用?
A: 兩者在爬行預算優化中的作用不同:
-
-
Disallow(在Robots.txt中): 告訴Google爬蟲「不要訪問這個頁面」。它會阻止爬蟲抓取頁面內容,從而節省Crawl Budget (爬行預算)。然而,如果這個頁面有外部連結,Google可能仍然會在搜尋結果中顯示其URL(沒有描述),並認為它可能需要被索引。noindex(在頁面<head>中): 告訴Google爬蟲「你可以訪問這個頁面,但不要將它收錄到索引中」。它不會直接節省Crawl Budget (爬行預算),因為爬蟲仍需抓取頁面才能看到noindex標籤。
-
選擇:
-
-
- 如果你想徹底阻止Google爬取和索引,且頁面沒有重要外部連結,可以使用
Disallow。 - 如果你想阻止頁面被索引,但又希望Google能夠訪問頁面(例如因為有很多外部連結,或頁面內容質量不低),那麼
noindex是更好的選擇。
- 如果你想徹底阻止Google爬取和索引,且頁面沒有重要外部連結,可以使用
-
要最大限度節省Crawl Budget (爬行預算),Disallow通常更直接。但要確保不要Disallow任何Google需要執行JS渲染或傳遞SEO 權重的頁面。
3. Q: 什麼情況下我需要特別關注Crawl Budget (爬行預算) 優化?
A: 以下情況你需要特別關注Crawl Budget (爬行預算) 優化:
-
-
- 大型網站: 頁面數量數萬甚至數百萬的網站。
- 內容更新頻繁的網站: 新聞網站、部落格、論壇等。
- 電商網站: 產品頁面多,且可能存在大量篩選參數導致的重複頁面。
- JavaScript動態內容網站: Google爬取JS內容比靜態HTML更耗資源。
- 網站索引問題嚴重: 許多重要頁面遲遲未被索引。
- 伺服器響應慢: 網站速度優化不足,導致Google爬蟲效率低下。
-
4. Q: 我該如何使用Google Search Console 爬取統計資料報告來找出Crawl Budget (爬行預算) 問題?
A: 在GSC的「設定」->「抓取統計資料」報告中,重點關注:
-
-
- 平均回應時間: 如果這個值很高,說明你的網站速度慢,影響Google 爬蟲效率。
- 按狀態碼分類的請求: 檢查是否有大量的4xx或5xx錯誤。大量的錯誤會浪費Crawl Budget (爬行預算)。
- 按檔案類型分類的請求: 看看Google爬蟲是否花了大量時間抓取JS、CSS或圖片,而不是HTML內容。
- 按Googlebot類型分類的請求: 確保重要的Googlebot(如通用Googlebot)在活動。 如果發現異常,就意味著存在爬行預算優化的機會。
-
5. Q: 內部連結優化如何幫助Crawl Budget (爬行預算) 優化?
A: 內部連結優化對Crawl Budget (爬行預算) 優化至關重要:
-
-
- 引導爬蟲: 強大且相關的內部連結系統,就像一張地圖,能引導Google爬蟲更輕鬆地發現你網站的所有重要頁面,減少尋路時間。
- 傳遞SEO 權重: 內部連結能將SEO 權重從高權重頁面傳遞給其他重要頁面,提升這些頁面的重要性,鼓勵Google爬蟲更頻繁地抓取。
- 減少孤立頁面: 確保所有重要頁面都有至少一個內部連結指向,避免它們成為「孤島」,不被爬蟲發現。
-
透過良好的內部連結優化和SEO 網站結構,可以有效提升Google 爬蟲效率,確保Crawl Budget (爬行預算) 用在最有價值的地方。